Clustering texts with an obvious grouping.
January 28, 2008 personal
It was pointed out to me by Kenny Easwaran that I ought to try clustering texts that already have a natural grouping.
So I ran the clustering program on 15 texts written by three authors, and here is the result:

The largest eigenvalue is 25 times bigger than the next largest eigenvalue, and picks out the author pretty well. The top pile consists of Jane Austen’s books (with Emma split into three volumes). The middle pile consists of Sir Arthur Conan Doyle’s books, with the Sherlock Holmes mysteries (Valley of Fear, Sign of Four, and Hound of the Baskervilles) grouped closer than the others. The bottom pile are five of Shakespeare’s plays.
Of course, these people are all pretty different. As requested below by Theo, let’s run it one more time, using 12 books from George Eliot, Jane Austen, and the Brontë sisters.
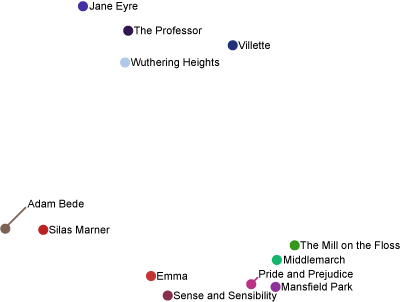
Well, that didn’t quite work. The books by the Brontë sisters (Wuthering Heights, Villette, The Professor, Jane Eyre) have been separated from the others, but George Eliot and Jane Austen are getting mixed together. Admittedly, if you just project to the y coordinate, the authors are sitting in disjoint intervals. Nevertheless, this isn’t as nice as I might hope; so let’s run it again, just on the eight books written by the two authors that aren’t being sufficiently separated:

I suppose this is somewhat better, though it’s basically just a stretched out and inverted version of the previous image. Jane Austen’s books (Sense and Sensibility, Pride and Prejudice, Mansfield Park, Emma) are all up on top, and George Eliot’s books still aren’t piled together.
You might have guessed that I have Project Gutenberg to thank for the text files (including the Shakespeare plays).